This data layer serves as the central source of information for various features such as tickers, price alerts, and token details. These features rely on the data within this layer to provide accurate and up-to-date information to users. In essence, it’s like the beating heart of the mochi ecosystem, ensuring that all the essential data is readily available for users to access and use.
Raw Data
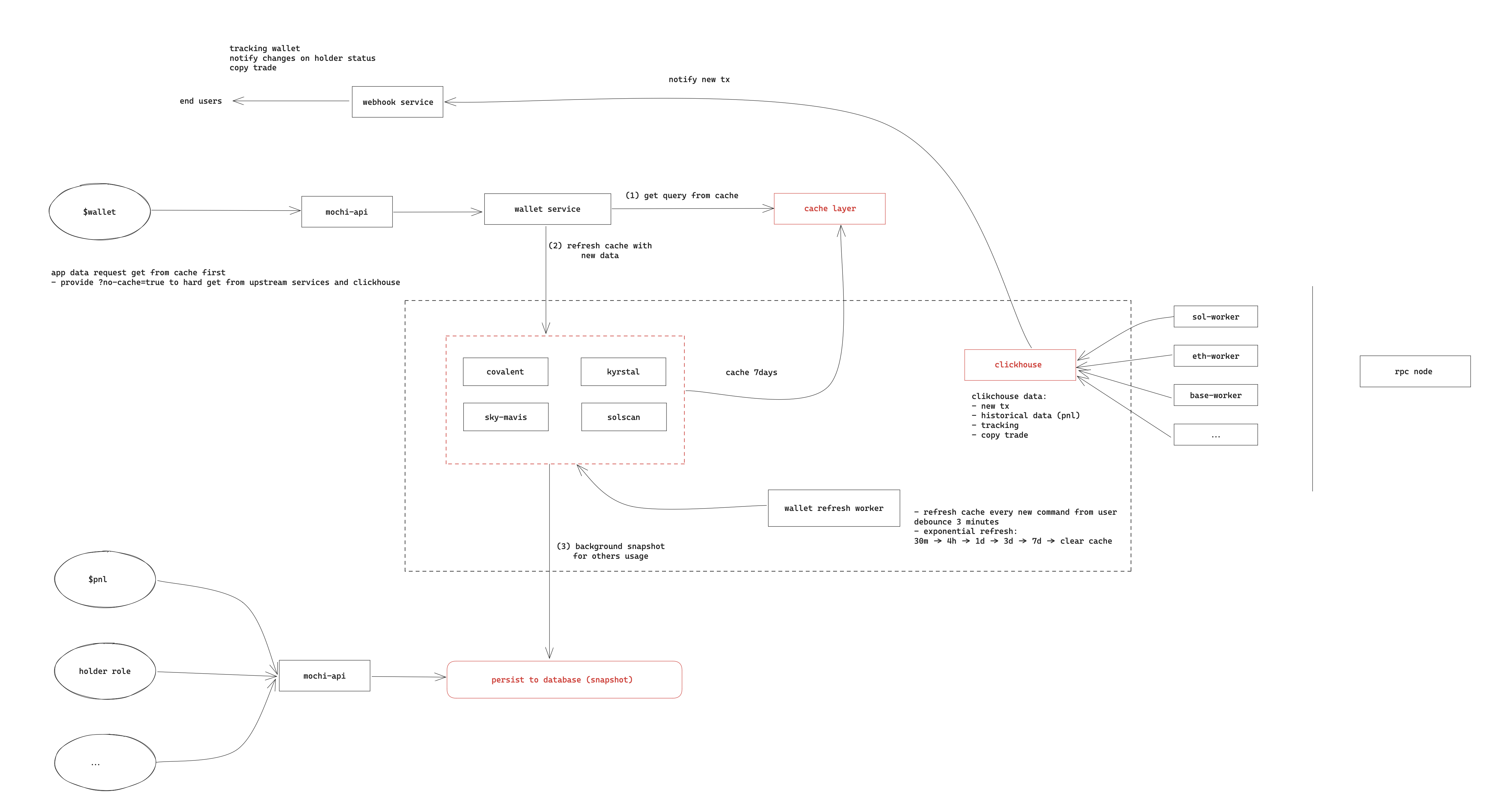
The raw data that powers our system originates from blockchain transaction data, which we can retrieve from various RPC sources. However, maintaining a stable and consistent RPC connection has proven to be challenging in our past experiences. To address this issue, we’ve adopted a different approach. We pull all the raw data into our Clickhouse database, where we store it for a period of 30 days before it’s automatically deleted.
This raw data plays a crucial role in providing transaction notifications to our users. Any transaction originating from wallets that we track is processed by our system. If a tracked wallet engages in a transaction, our system ensures that users are promptly notified about it. This process allows us to deliver real-time transaction updates and information to our users reliably.
Token data
Token data encompasses several important aspects:
Token Info: This component provides project metadata, including details such as the project’s Twitter account, website, and a concise project description. We retrieve this information from sources like Etherscan or CoinGecko.
Price Info: Calculating price information ourselves can be redundant and resource-intensive. Instead, we rely on established sources like CoinGecko, which offers a stable API with reasonable costs. This allows us to provide accurate and up-to-date price data to our users without reinventing the wheel.
Dex Data: Dex data represents the most comprehensive information about each token. It includes details about which decentralized exchanges (dex) currently list the token and provides data such as the number of token holders or trading volume for each day. Rather than calculating this information in-house, we source it from multiple data sources and store it in our data layer. This approach ensures that our users have access to comprehensive dex-related data for each token without the need for extensive calculations on our part.
Gotchas
Query speed
When it comes to building online services, speed is a top priority. As our data layer continues to grow, we’ve implemented several optimization strategies to ensure efficient and fast data retrieval:
Caching Frequently Accessed Data: To address the need for frequently queried data like token prices and metadata (such as emoji associated with tokens), we employ short-lived Redis caching. This allows us to store this data temporarily in a highly responsive cache, reducing the need to query the upstream services or databases repeatedly for the same information. Caching helps deliver swift responses to user requests.
Read Replicas and Data Partitioning: For data that cannot be cached due to its infrequent use or size, we’ve taken a two-pronged approach. First, we’ve created read replicas within our PostgreSQL layer. These replicas serve as copies of our main database, dedicated to handling read requests. This not only spreads the load but also improves query response times.
Additionally, we’ve optimized data storage and retrieval by partitioning our most frequently accessed tables. Partitioning involves breaking these tables into smaller, more manageable parts based on certain criteria (e.g., time, category, or other relevant factors). This partitioning strategy significantly enhances query performance, as it reduces the amount of data that needs to be scanned or processed during each query. This combination of read replicas and data partitioning ensures that we can maintain high-speed access to our data even as our data layer continues to expand.
Data Realtime-ness
Ensuring real-time data accuracy for crucial information like token prices is essential to avoid missing any market movements. However, for certain types of data like total assets and token info, real-time updates can be delayed without significantly impacting user experience. Here’s how we manage this balance:
Real-time Data for Price Updates: For data that requires real-time accuracy, such as token prices, we prioritize instant updates. This ensures that our users receive the most up-to-date information, especially those who rely on timely market data. Real-time data is essential to provide users with the information they need to make informed decisions in the fast-paced world of cryptocurrencies.
Delayed Data for Less Critical Information: To reduce stress on our system and enhance the overall user experience, we introduce a slight delay in updating less critical information, such as total assets and token details. This delay allows us to optimize data processing and avoid overwhelming our resources. From the perspective of most users, this data still appears to be served instantly, ensuring a seamless experience.
Prioritizing Real-time Data for Top Users: Recognizing the importance of real-time data for our top users, we’ve implemented a ranking system. The most active users or those with specific access privileges can enjoy the benefit of receiving data in real-time with minimal delay. This approach ensures that our highest-priority users have access to the most critical data without compromise.
Background Jobs for Data Handling: To manage these data updates efficiently, we handle most data processing as background jobs. This allows us to update and synchronize information without disrupting the user interface or slowing down the system’s responsiveness. By running these tasks in the background, we maintain a balance between real-time data needs and system stability.
In summary, our approach involves a careful balance between real-time data for critical information and slightly delayed updates for less critical data. This strategy, combined with a ranking system and background job processing, allows us to provide both real-time accuracy and a smooth user experience while managing system resources effectively.
Maintain an affordable SaSS/infras price
Maintaining a reasonable cost for the data layer is crucial for the sustainability of your online service. Here’s how you approach cost management:
- Start with Third-Party Services: When in doubt, opting for third-party services is often the most cost-effective and efficient choice. These services are specialized and can save you time and resources in the short term. Even if they come with a monthly cost, as you mentioned, they often offer a great value proposition by allowing you to focus on other aspects of your platform.
- Continuous Evaluation: Periodically assess the cost-effectiveness of the third-party services you use. Determine if the expense is justified by the benefits they provide. If a service becomes too costly or if you outgrow it, consider alternatives or building an in-house solution.
- Building In-House Solutions: As your platform matures and your needs become more complex, it may become financially prudent to build certain services in-house. By doing so, you have more control over costs, scalability, and customization. However, this should be a well-considered decision, as it often involves higher initial investments in development and ongoing maintenance.
- Cost Monitoring and Optimization: Implement robust cost monitoring and optimization practices. Keep an eye on data usage, query efficiency, and infrastructure costs. Use cloud provider tools to track spending and optimize resources accordingly. Often, small adjustments can lead to significant cost savings.